
Project information
- Category: NLP / Information Retrieval
- Technologies: FAISS, Llama 3, PyTorch, Flask
- Performance: Near real-time response latency
FAISS Optimized Information Retrieval System
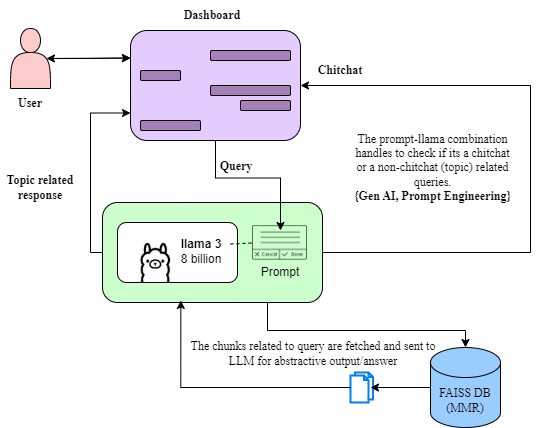
This project represents a sophisticated end-to-end information retrieval system that combines the power of FAISS-based semantic search with Llama 3 for intelligent conversational response generation. The system is designed to handle large-scale document retrieval tasks with exceptional speed and accuracy.
Technical Architecture:
Dense Vector Embeddings: The system leverages dense vector embeddings generated from a comprehensive corpus of domain-specific Wikipedia data, encompassing over 50,000+ articles. These embeddings capture semantic meaning and relationships between documents, enabling more intelligent retrieval compared to traditional keyword-based methods.
FAISS Indexing: Facebook AI Similarity Search (FAISS) is employed for efficient similarity search and clustering of dense vectors. FAISS enables the system to search through millions of vectors in milliseconds, making real-time information retrieval possible even with large document collections.
Maximum Marginal Relevance (MMR): To optimize the relevance-diversity trade-off during retrieval, the system implements MMR algorithms. This ensures that retrieved documents are not only relevant to the query but also diverse, providing users with comprehensive coverage of the topic.
Semantic Clustering: Advanced semantic clustering techniques group similar documents together, improving retrieval accuracy and enabling the system to understand hierarchical relationships within the knowledge base.
Intelligent Response Generation:
Llama 3 Integration: The system integrates Meta's Llama 3 language model for generating conversational responses. Retrieved documents are passed as context to Llama 3, which synthesizes the information into coherent, natural language responses.
Query-Type Inference: The system employs sophisticated query-type inference to understand user intent. This allows it to adjust retrieval strategies and response generation based on whether the query is factual, exploratory, comparative, or conversational.
Context-Aware Reasoning: By maintaining context across interactions, the system can handle follow-up questions and multi-turn conversations effectively, providing a more natural user experience.
Performance Optimization:
CUDA Acceleration: The entire pipeline is optimized for GPU acceleration using CUDA, enabling near real-time response latency. This is crucial for user experience, especially when dealing with complex queries that require extensive document retrieval and generation.
Flask Web Interface: A lightweight Flask-based web interface provides easy access to the system, allowing users to interact with the retrieval system through a clean, intuitive interface. The interface supports both simple queries and advanced search parameters.
Key Achievements:
- Successfully indexed and made searchable 50,000+ Wikipedia articles
- Achieved near real-time response latency through CUDA-accelerated retrieval
- Implemented sophisticated MMR algorithms for optimal relevance-diversity balance
- Integrated state-of-the-art language model (Llama 3) for natural response generation
- Built scalable architecture capable of handling concurrent user requests
Applications:
This system has broad applications in knowledge management, question-answering systems, research assistance, and intelligent document search. The combination of efficient retrieval and intelligent generation makes it suitable for enterprise knowledge bases, educational platforms, and research repositories.